Download files directly on servers
Problem
Increasingly often, I have to download large files which are available only via redirects after tricky authentication (e.g. Kaggle datasets or Google Takeout archives).
Ideally, I would like to download these files directly on my servers instead of downloading them first on my local machine and then uploading it in two steps. It would prevent wasting bandwidth and would be faster. These servers usually do not have any GUI applications installed on them. Hence, we don’t have access to a web browser running on the server.
However, because of the extra authentication checks, doing it with cURL is usually not as trivial as right clicking a link and copying its address. Moreover, [Lynx](https://en.wikipedia.org/wiki/Lynx_(web_browser) usually does not cut it when it comes to complex Javascript based redirects. In those cases, this is what you can do. However, both Chrome and Firefox allow exporting requests made using the browser to a format amenable for cURL, which could solve our problem.
Solution
Let’s say you are on a Data Download page with some files on it (these aren’t particularly large files, but enough for a demonstration):
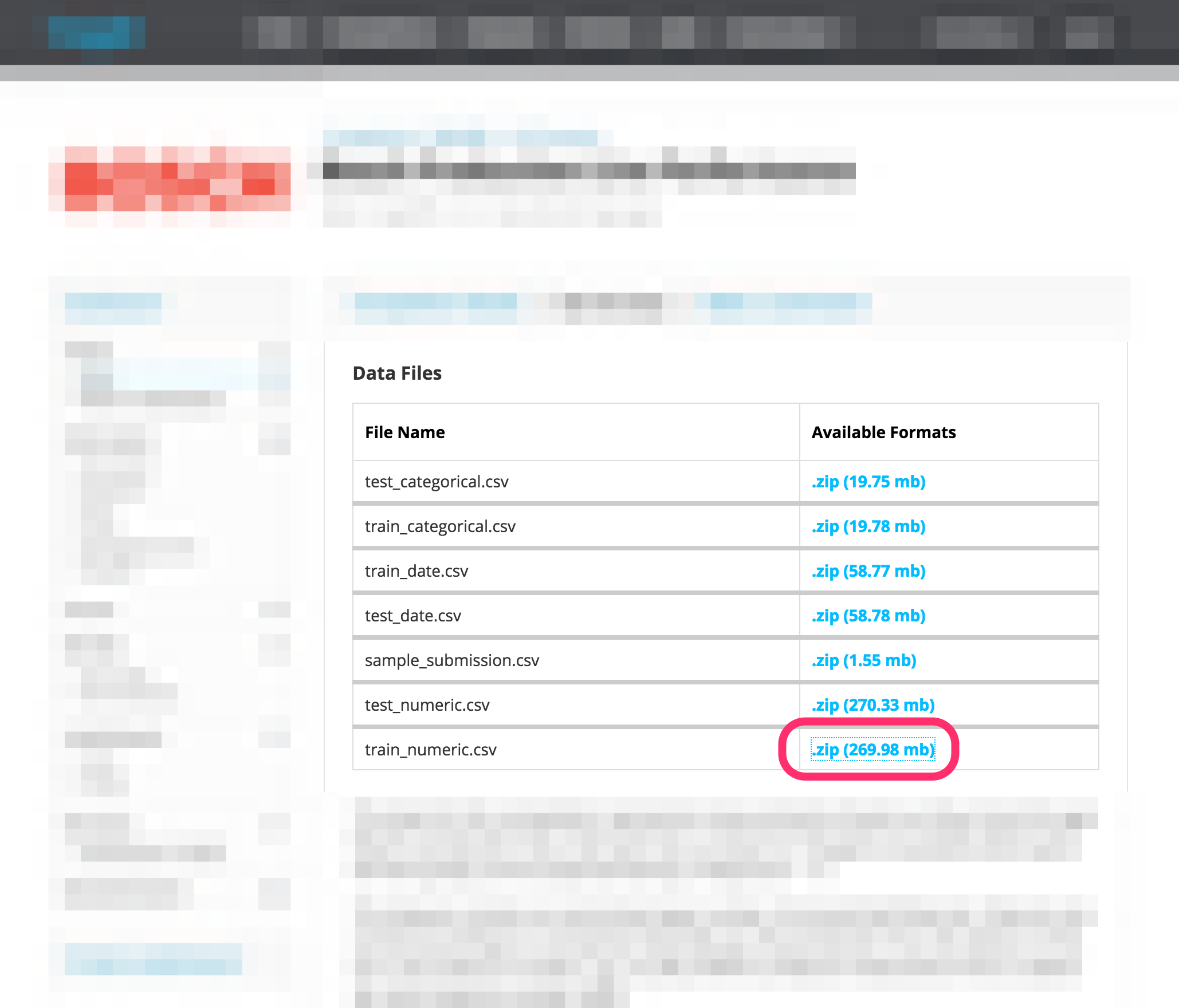
Open the DevTools using your preferred method, or Network Monitor on Firefox.
If needed, turn on Preserve logs across pages. Then click on the link to download the file.
The requests on the Network monitor panel should look like the following:
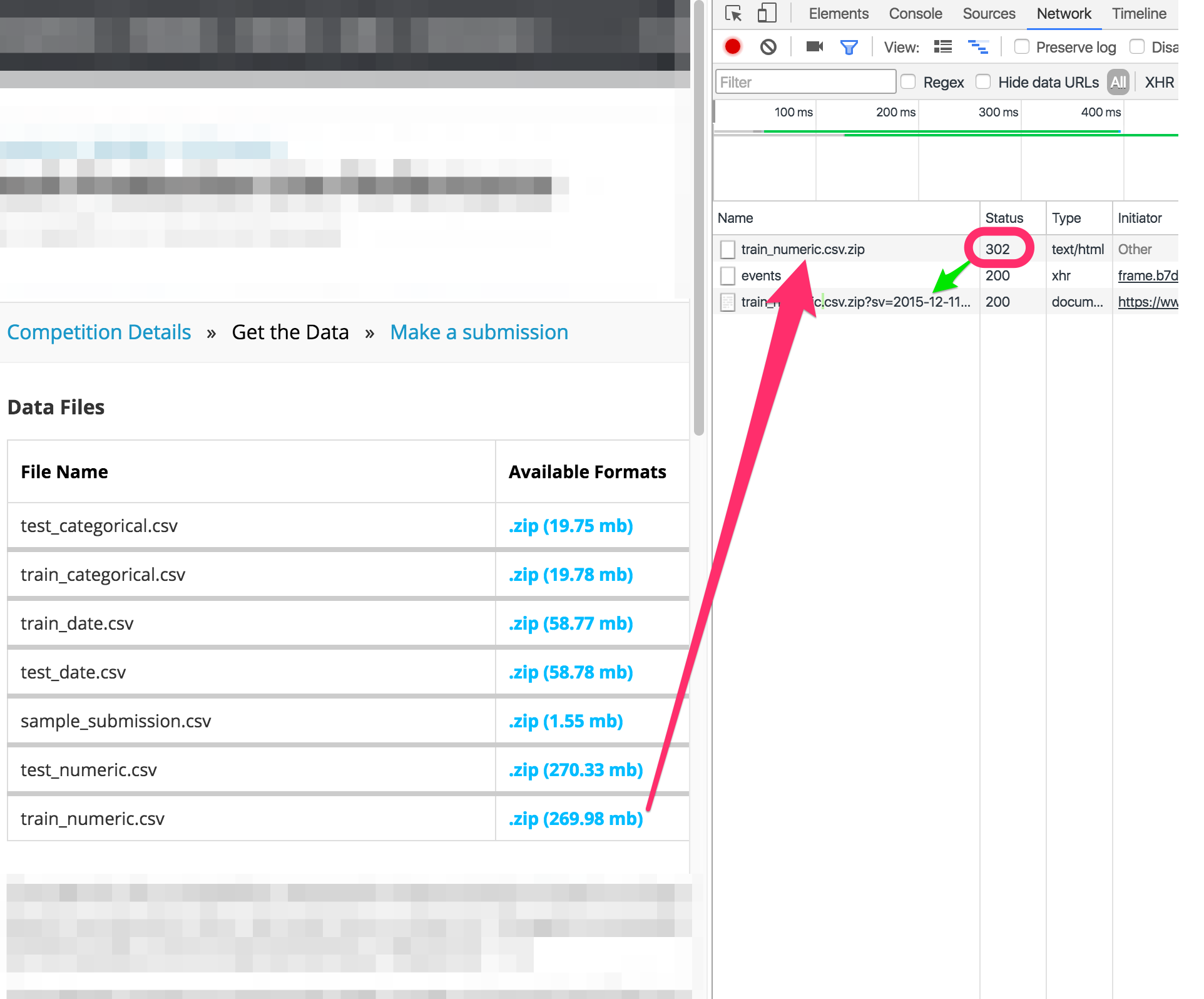
Finally, right click on the redirected URL, and copy the request as cURL:
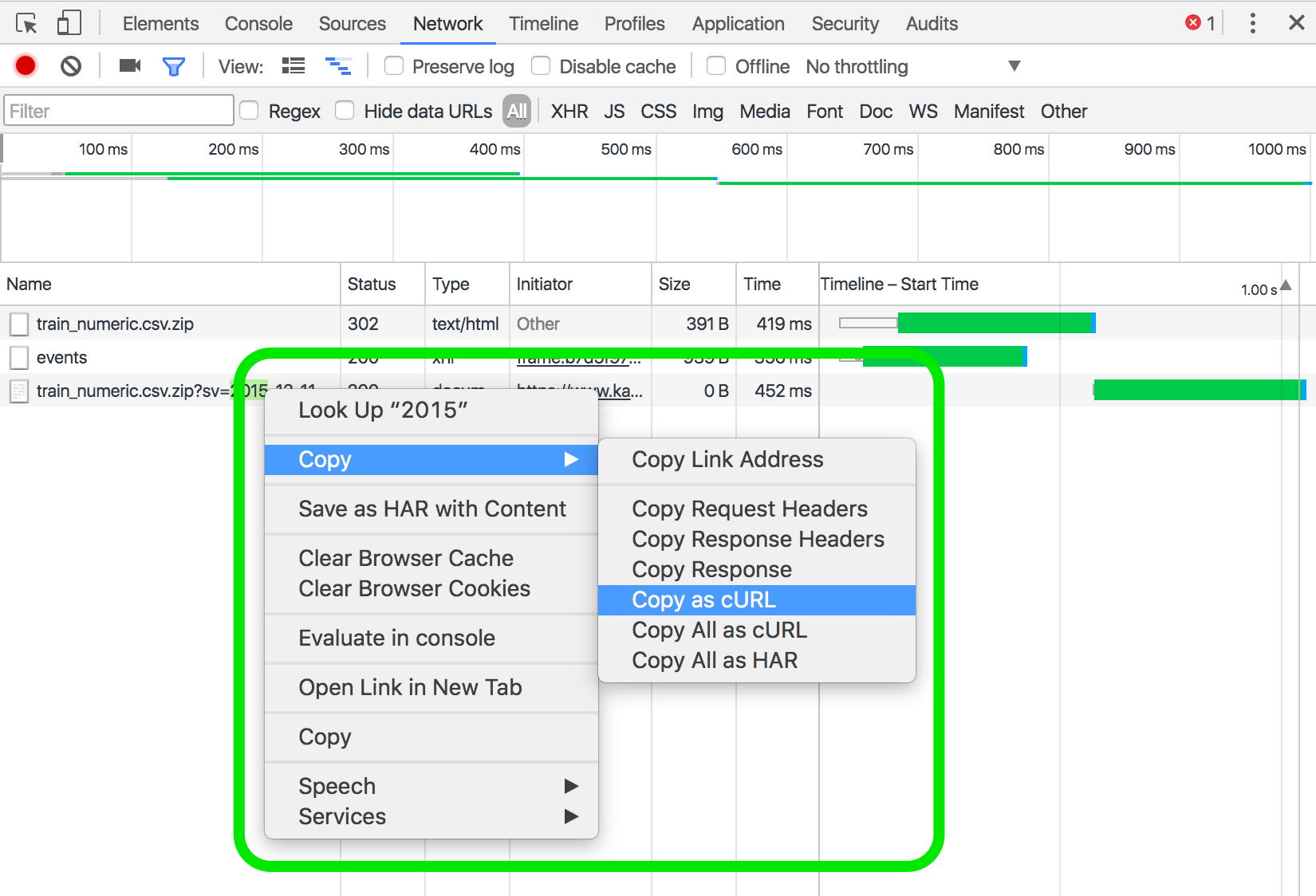
Then you can SSH into your server, paste the cURL command and start the download there.
Consider using screen or tmux on the remote server to avoid interrupting your download in case your connection to the server fails.
Caveats
Usually the links are short-lived (because the authentication just needs to be active for as long as the browser needs to redirect to the correct link) and, hence, the actions need to be taken rather quickly. However, developers are usually a little lax about the duration the link remains active to allow people on very high latency networks to access the data as well. Hence, the time is usually not less than, say, 30 seconds.
Another thing to consider is that since the copied curl request will contain sensitive cookies in plain text, you may want to prepend the command with a space to avoid storing it in the bash history on the server.